
Redes neuronales: así de sencillo (Parte 43): Dominando las habilidades sin función de recompensa

Introducción
El aprendizaje por refuerzo es un potente enfoque del aprendizaje automático que permite a un agente aprender de forma autónoma interactuando con el entorno y recibiendo realimentación en forma de función de recompensa. No obstante, uno de sus problemas clave es la necesidad de definir una función de recompensa que formalice el comportamiento deseado del agente.
Esto puede ser un arte difícil, especialmente en tareas en las que se requieren múltiples objetivos o existen situaciones ambiguas. Además, algunas tareas pueden no tener una función de recompensa explícita, lo cual dificulta la aplicación de los métodos tradicionales de aprendizaje por refuerzo.
En este artículo, le introduciremos al concepto "Diversity is All You Need" ("la diversidad es todo lo que necesitas"), que permite entrenar un modelo para adquirir habilidades sin una función de recompensa explícita. La variedad de acciones, la exploración del entorno y la maximización de la variabilidad de las interacciones con el entorno son factores clave para enseñar a un agente a comportarse de forma eficaz.
Este enfoque ofrece una nueva perspectiva sobre el aprendizaje sin una función de recompensa y puede resultar útil en tareas complejas en las que definir una función de recompensa explícita es difícil o imposible.
1. El concepto "Diversity is All You Need".
En la vida real, se requieren determinados conocimientos y habilidades para que un artista pueda desempeñar ciertas funciones. Del mismo modo, al entrenar un modelo, queremos desarrollar las habilidades necesarias para resolver la tarea en cuestión.
En el aprendizaje por refuerzo, la principal herramienta para estimular el modelo es la función de recompensa: esta permite al agente comprender el éxito de sus acciones. No obstante, las recompensas suelen recibirse con poca frecuencia y se requieren enfoques adicionales para encontrar soluciones óptimas. Ya hemos visto algunos métodos para estimular el modelo para que explore el entorno, pero no siempre son eficaces.
Los modelos entrenados de la forma tradicional tienen una especialización estrecha y solo son capaces de resolver tareas específicas. Con la aparición de pequeños cambios en el enunciado del problema, se requiere un reentrenamiento completo del modelo, aunque las habilidades ya existentes puedan resultar útiles. Lo mismo ocurre al cambiar el entorno.
Una posible respuesta a este problema sería usar modelos jerárquicos de unidades múltiples. En estos modelos, creamos modelos aparte para las distintas habilidades y un planificador que gestiona el uso de estas. Entrenar un planificador nos permite resolver nuevos problemas usando habilidades previamente entrenadas. Sin embargo, aquí surgen dudas sobre la suficiencia y calidad de las habilidades preentrenadas, ya que las nuevas tareas pueden requerir habilidades adicionales.
El concepto "Diversity is All You Need" sugiere utilizar modelos jerárquicos con habilidades separadas y un planificador, haciendo hincapié en maximizar la diversidad de acciones y la exploración del entorno, lo cual permite al agente aprender y adaptarse eficazmente. Al enseñar habilidades diversas y distinguibles, el modelo se vuelve más flexible y adaptable, capaz de usar diferentes estrategias en distintas situaciones. Este enfoque resulta útil cuando definir recompensas explícitas supone un reto, ya que permite a los modelos explorar y encontrar nuevas soluciones de forma autónoma.
La idea central de este concepto consiste en utilizar la diversidad como herramienta de entrenamiento. La diversidad de acciones y comportamientos del modelo permite explorar el espacio de estados y descubrir nuevas posibilidades. La diversidad no se limita a acciones aleatorias o ineficaces, sino que pretende descubrir distintas estrategias útiles que puedan aplicarse en situaciones distintas.
El principio "Diversity is All You Need" implica que la diversidad es un componente clave del éxito del aprendizaje sin una función de recompensa explícita. Un modelo entrenado en diversas habilidades se vuelve más flexible y adaptable, capaz de aplicar distintas estrategias según el contexto y los requisitos de la tarea.
Este enfoque tiene aplicaciones potenciales en problemas complejos en los que la definición de una función de recompensa explícita resulta difícil o no está disponible. Permite al modelo explorar el entorno por sí mismo, aprendiendo distintas habilidades y estrategias que pueden ayudarle a descubrir nuevos caminos y soluciones.
Otro postulado subyacente al concepto "Diversity is All You Need" es la suposición de que el estado actual del modelo depende no solo de la acción específica elegida, sino también de la habilidad utilizada. Es decir, en lugar de asociar simplemente acción y estado, el modelo aprenderá a asociar determinados estados con determinadas habilidades.
El algoritmo conceptual consta de dos pasos. Inicialmente, se implementa el aprendizaje no supervisado de una serie de habilidades sin conexión con una tarea específica, lo cual permite explorar a fondo el entorno y ampliar el repertorio de comportamientos del agente. A esto le sigue una fase de aprendizaje supervisado por refuerzo destinada a maximizar el rendimiento del modelo en la resolución de la tarea establecida.
En la primera fase, entrenaremos el modelo para aprender las habilidades. Los datos de entrada del modelo serán el estado actual del entorno y la habilidad específica seleccionada para la aplicación. El modelo generará la acción correspondiente, que se ejecutará a continuación. El resultado de esta acción será la transición a un nuevo estado del entorno. En esta fase, solo nos interesará este nuevo estado: la recompensa externa no se utilizará.
En su lugar, aplicaremos un modelo de discriminador que intentará determinar a partir del nuevo estado qué habilidad se ha utilizado en el paso anterior. La entropía cruzada entre los resultados del discriminador y el vector one-hot correspondiente a la habilidad aplicada servirá como recompensa para nuestro modelo de habilidades.
El entrenamiento del modelo de habilidades se realizará mediante técnicas de aprendizaje por refuerzo como Actor-Crítico. El modelo de discriminador, por su parte, se entrenará utilizando métodos de aprendizaje supervisado clásicos.
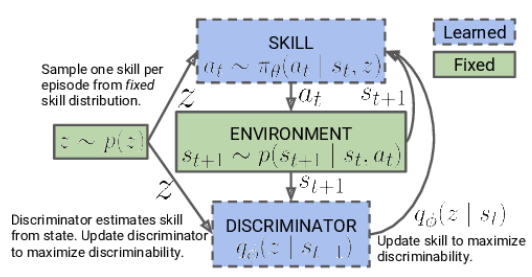
Al principio del entrenamiento del modelo de habilidades, trabajaremos con una base de habilidades fija que será independiente del estado actual. Esto se debe a que aún no disponemos de información sobre las habilidades y su utilidad en los distintos estados. Nuestro reto consistirá en aprender estas habilidades. Al desarrollar la arquitectura del modelo, determinaremos el número de habilidades que se entrenarán.
En el proceso de aprendizaje de un modelo de habilidades, el agente explorará activamente y completará cada habilidad basándose en la información del entorno. Luego suministraremos los identificadores de habilidades al modelo de forma aleatoria para que este pueda aprender y rellenar cada habilidad independientemente de las demás.
El modelo utilizará los identificadores de habilidad obtenidos y el estado actual del entorno para determinar la acción adecuada a realizar. Asimismo, aprenderá a asociar determinadas habilidades con estados específicos y a elegir acciones para cada habilidad.
Debemos señalar que, al principio del entrenamiento, el modelo no tendrá conocimiento previo de las habilidades ni de su utilidad en determinados estados: el modelo explorará e identificará de forma independiente las conexiones entre habilidades y estados en el proceso de entrenamiento. Para ello utilizará una función de recompensa que estimulará la máxima variación del comportamiento del agente según la habilidad aplicada.
Una vez completada la fase de entrenamiento del modelo de habilidades, pasaremos a la siguiente fase, que será el aprendizaje por refuerzo supervisado. En este paso, entrenaremos el modelo del planificador con el objetivo de maximizar un objetivo dado o maximizar la recompensa dentro de una tarea determinada. En este proceso, podremos utilizar un modelo de habilidades fijo para acelerar el proceso de aprendizaje del modelo del planificador.
Así, el enfoque en dos fases del entrenamiento del modelo de habilidades, que comenzará con el rellenado de habilidades sin supervisión y terminara con el aprendizaje por refuerzo supervisado, permitirá que el modelo aprenda y utilice las habilidades de forma independiente en todas las tareas.
Obsérvese que en nuestro planteamiento hemos cambiado el proceso jerárquico de toma de decisiones respecto al modelo jerárquico anteriormente comentado. Antes usábamos varios agentes, cada uno con sus propias habilidades. Los agentes ofrecían opciones de actuación y luego el planificador las evaluaba y tomaba la decisión final.
En el enfoque actual, hemos invertido esta secuencia: ahora, el planificador analiza primero la situación actual y decide cuál es la habilidad adecuada. A continuación, el agente decidirá la acción correspondiente según la habilidad seleccionada.
Así, hemos invertido el proceso jerárquico: ahora el planificador decidirá qué habilidad utilizar y, a continuación, el agente realizará la acción correspondiente a la habilidad elegida. Este cambio nos permitirá gestionar y utilizar eficazmente las competencias en función de la situación actual.
2. Implementación usando MQL5
Tras la revisión teórica, vamos a pasar a la realización práctica de nuestro trabajo. Como en el artículo anterior, empezaremos creando una base de datos de ejemplos que usaremos para entrenar el modelo. La recogida de datos la realizará el asesor experto "DIAYN\Research.mq5", que es una versión modificada del asesor experto del artículo anterior. Sin embargo, hay algunas diferencias en el algoritmo actual:
el primer cambio que hemos implementado tiene que ver con la arquitectura de los modelos. Hemos realizado modificaciones en la arquitectura para cumplir los nuevos requisitos y las ideas derivadas del concepto "Diversity is All You Need".
Así, utilizaremos tres modelos en nuestro proceso de entrenamiento:
- Un modelo de agente (habilidades). Se encargará de aprender y poner en práctica diversas habilidades en función del estado actual del entorno.
- Un planificador, que tomará decisiones basándose en una evaluación de la situación y seleccionará la habilidad adecuada para la tarea. El planificador trabajará en cooperación con el modelo de habilidades e gestionará la toma de decisiones de alto nivel.
- Un discriminador, que solo se utilizará durante el entrenamiento del modelo de habilidades y no se aplicará en tiempo real. Se utilizará para proporcionar realimentación y servirá para calcular las recompensas durante el entrenamiento.
Debemos señalar que el modelo de habilidades y el planificador son los principales modelos que se utilizarán en el proceso de explotación a gran escala y en el proceso de resolución de problemas. El discriminador, por su parte, solo se utilizará para mejorar el entrenamiento del modelo de habilidades y no se empleará en el funcionamiento real del sistema.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *scheduler, CArrayObj *discriminator) { //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } //--- if(!scheduler) { scheduler = new CArrayObj(); if(!scheduler) return false; } //--- if(!discriminator) { scheduler = new CArrayObj(); if(!scheduler) return false; }
Según el algoritmo "Diversity is All You Need", al modelo de agente (modelo de habilidades) se le suministrará una entrada de búfer de datos que contendrá las descripciones del estado actual y el identificador de la habilidad que se está utilizando. En el contexto de nuestro trabajo, transmitiremos la siguiente información:
- Los datos históricos de los movimientos de precio y los indicadores: Estos datos ofrecerán información sobre las variaciones pasadas de los precios en el mercado y los valores de diversos indicadores, y servirán de contexto importante para la toma de decisiones del modelo de agente.
- La información sobre el estado actual de la cuenta y las posiciones abiertas: Estos datos incluirán información sobre el balance actual de la cuenta, las posiciones abiertas, el tamaño de las posiciones y otros indicadores financieros. Asimismo, ayudarán al modelo de agente a considerar la situación actual y las limitaciones a la hora de tomar decisiones.
- El vector one-hot de identificación de habilidades: Este vector supondrá una representación binaria del identificador de la habilidad que se está utilizando. Indicará la habilidad específica que el modelo de agente debe aplicar en un estado determinado.
Para procesar dicha información, necesitaremos una capa de datos de entrada de tamaño suficiente para permitir que el modelo de agente obtenga toda la información necesaria sobre las condiciones del mercado, los datos financieros y la habilidad seleccionada para tomar decisiones óptimas.
//--- Actor actor.Clear(); CLayerDescription *descr; //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (int)(HistoryBars * BarDescr + AccountDescr + NSkills); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Tras recibir los datos de entrada, crearemos una capa de normalización de datos que desempeñará un papel importante en el procesamiento de los datos de entrada antes de transmitirlos al modelo de agente. La capa de normalización de datos permitirá poner a la misma escala diferentes característica de origen, lo cual garantizará la estabilidad y coherencia de los datos. Esto resulta esencial para que el modelo de agente funcione eficazmente y produzca resultados de calidad.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Los datos de origen preparados pueden procesarse usando un bloque de capas convolucionales.
Las capas convolucionales son un componente clave en la arquitectura de los modelos de aprendizaje profundo, especialmente en tareas de procesamiento de imágenes y secuencias, y permiten extraer dependencias espaciales y locales de los datos de origen.
En el caso de nuestro algoritmo "Diversity is All You Need", las capas convolucionales pueden aplicarse a datos históricos de movimientos de precio e indicadores para extraer patrones y tendencias importantes. Esto ayudará al agente a captar las relaciones entre los distintos pasos temporales y a tomar una decisión basada en los patrones detectados.
Cada capa convolucional consta de 4 filtros que explorarán los datos de entrada con una ventana específica. La aplicación de operaciones convolucionales dará como resultado un conjunto de mapas de características que resaltarán características importantes de los datos. Estas transformaciones permitirán al modelo de agente detectar y considerar características importantes de los datos en el contexto de una tarea de aprendizaje por refuerzo.
Las capas convolucionales proporcionarán al modelo de agente la capacidad de "ver" aspectos significativos de los datos y centrarse en ellos, lo cual constituye un paso importante en el proceso de toma de decisiones y actuación de "Diversity is All You Need".
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; prev_count = descr.count = prev_count; descr.window = 4; descr.step = 4; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Tras pasar por el bloque de capas convolucionales, los datos se procesarán en el bloque de decisión, que consta de tres capas totalmente conectadas. Mientras los datos pasan a través de las capas totalmente conectadas, el modelo de agente será capaz de explorar dependencias complejas y descubrir relaciones entre distintos aspectos de los datos.
En la salida de la unidad de decisión se utilizará la función cuantil totalmente parametrizada (FQF). Este modelo se usará para estimar los cuantiles de la distribución de recompensas futuras o las variables objetivo. Permitirá al modelo de agente no solo obtener estimaciones de los valores medios, sino también predecir diferentes cuantiles, lo cual resultará útil para modelar la incertidumbre y la toma de decisiones en condiciones de estocasticidad.
El uso de un modelo FQF totalmente parametrizado a la salida de la unidad de decisión permitirá al modelo de agente producir predicciones más flexibles y precisas que pueden utilizarse para seleccionar acciones de forma óptima en el marco de "Diversity is All You Need".
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 128; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = NActions; descr.window_out = 32; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
El modelo de programación realizará una clasificación del estado actual del entorno para determinar la habilidad que debe utilizarse. A diferencia del modelo de agente, el planificador tiene una arquitectura simplificada sin uso de capas convolucionales para el preprocesamiento de datos, lo que permite ahorrar recursos.
Los datos de entrada para el planificador son similares a los del agente, salvo por el vector de identificación de habilidades. El planificador recibe una descripción del estado actual del entorno, incluidos los datos históricos del movimientos de precios, los indicadores y la información sobre el estado actual de la cuenta y las posiciones abiertas.
La clasificación del estado del entorno y la determinación de la habilidad a usar se realizará pasando los datos a través de las capas completamente conectadas y el bloque FQF. Los resultados se normalizarán usando la función SoftMax, lo que dará como resultado un vector de probabilidades que reflejará la probabilidad de que un estado pertenezca a cada habilidad posible.
Así, el modelo de planificador nos permitirá determinar qué habilidad debe utilizarse según el estado actual del entorno. Esto ayudará además al modelo de agente a tomar la decisión adecuada y elegir la acción óptima según el concepto "Diversity is All You Need".
//--- Scheduler scheduler.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr + AccountDescr); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = NSkills; descr.window_out = 32; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = NSkills; descr.step = 1; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
Para diversificar las habilidades, utilizaremos un tercer modelo: el Discriminador. Su objetivo será recompensar las acciones más inesperadas, lo cual fomentará la diversidad del comportamiento del Agente. La precisión de este modelo no será necesaria a un alto nivel, por lo que hemos decidido simplificar aún más su arquitectura y eliminar el bloque FQF.
En la arquitectura del discriminador, solo utilizaremos la capa de normalización y las capas completamente conectadas. De esta forma se reducirán los recursos informáticos al tiempo que se mantendrá la capacidad de clasificación del modelo. En la salida del modelo, aplicaremos la función SoftMax para obtener las probabilidades de las acciones pertenecientes a distintas habilidades.
//--- Discriminator discriminator.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr + AccountDescr); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NSkills; descr.optimization = ADAM; descr.activation = None; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = NSkills; descr.step = 1; descr.optimization = ADAM; if(!discriminator.Add(descr)) { delete descr; return false; } //--- return true; }
Tras describir la arquitectura de los modelos, podremos comenzar a organizar el proceso de recogida de datos para el entrenamiento. En la primera fase de recogida de datos, solo utilizaremos el modelo de agente, ya que no dispondremos de información primaria sobre el entorno. En su lugar, podemos utilizar un vector de identificación de habilidades generado aleatoriamente que producirá resultados comparables usando un modelo no entrenado. También nos permitirá reducir considerablemente el uso de recursos informáticos.
El método OnTick organizará el propio proceso de recogida de datos. Al principio del método, comprobaremos si se ha producido un nuevo evento de apertura de barra y, en caso afirmativo, cargaremos los datos históricos.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh();
De forma similar al artículo anterior, cargaremos la información del estado actual en dos arrays: el array de datos históricos state y el array de información sobre el estado de la cuenta account de la estructura sState.
MqlDateTime sTime; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; TimeToStruct(Rates[b].time, sTime); float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); float atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- sState.state[b * 12] = (float)Rates[b].close - open; sState.state[b * 12 + 1] = (float)Rates[b].high - open; sState.state[b * 12 + 2] = (float)Rates[b].low - open; sState.state[b * 12 + 3] = (float)Rates[b].tick_volume / 1000.0f; sState.state[b * 12 + 4] = (float)sTime.hour; sState.state[b * 12 + 5] = (float)sTime.day_of_week; sState.state[b * 12 + 6] = (float)sTime.mon; sState.state[b * 12 + 7] = rsi; sState.state[b * 12 + 8] = cci; sState.state[b * 12 + 9] = atr; sState.state[b * 12 + 10] = macd; sState.state[b * 12 + 11] = sign; }
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); sState.account[2] = (float)AccountInfoDouble(ACCOUNT_MARGIN_FREE); sState.account[3] = (float)AccountInfoDouble(ACCOUNT_MARGIN_LEVEL); sState.account[4] = (float)AccountInfoDouble(ACCOUNT_PROFIT); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; int total = PositionsTotal(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += PositionGetDouble(POSITION_PROFIT); break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += PositionGetDouble(POSITION_PROFIT); break; } } sState.account[5] = (float)buy_value; sState.account[6] = (float)sell_value; sState.account[7] = (float)buy_profit; sState.account[8] = (float)sell_profit;
Luego almacenaremos la estructura resultante en una base de datos de ejemplos para el posterior entrenamiento del modelo. Deberemos crear un búfer de datos para transferir los datos de origen al modelo de Agente. En este caso, empezaremos cargando los datos históricos en este búfer.
State1.AssignArray(sState.state);
Para que el modelo resulte más sólido e igualmente eficaz con cuentas de distintos tamaños, hemos decidido convertir la información del estado de la cuenta en unidades relativas. Para ello, realizaremos algunos cambios en los indicadores de estado de la cuenta.
En lugar del valor absoluto del balance, utilizaremos el coeficiente de variación del balance. Esto permitirá considerar el cambio relativo del balance a lo largo del tiempo.
También sustituiremos la medida de la equidad propia por la relación entre la equidad y el balance. Esto ayudará a contabilizar la parte relativa de la equidad propia en relación con el balance, y a que la cifra resulte más comparable entre las distintas cuentas.
Además, añadiremos la relación entre la variación de la equidad propia y el balance para tener en cuenta la variación respecto a la equidad propia a lo largo del tiempo.
Por último, introducimos el coeficiente de ganancias/pérdidas acumuladas con respecto al balance para considerar la magnitud relativa de los resultados comerciales acumulados respecto al balance de la cuenta.
Estos cambios permitirán crear un modelo más versátil que pueda gestionar con eficacia diferentes tamaños de cuenta y considerar su estado relativo.
State1.Add((sState.account[0] - prev_balance) / prev_balance); State1.Add(sState.account[1] / prev_balance); State1.Add((sState.account[1] - prev_equity) / prev_equity); State1.Add(sState.account[3] / 100.0f); State1.Add(sState.account[4] / prev_balance); State1.Add(sState.account[5]); State1.Add(sState.account[6]); State1.Add(sState.account[7] / prev_balance); State1.Add(sState.account[8] / prev_balance);
Tras finalizar la preparación de los datos para el modelo, crearemos un vector one-hot aleatorio que servirá como identificador de la habilidad. Un vector one-hot es un vector binario en el que solo un elemento es 1, mientras que los demás elementos son 0. De este modo, el modelo podrá distinguir e identificar las distintas habilidades según el valor del elemento correspondiente a una habilidad concreta.
La creación de un vector one-hot aleatorio garantizará que los identificadores de habilidades de cada muestra de datos sean diversos y distintos, lo cual se ajustará a nuestro concepto de "Diversity is All You Need".
vector<float> one_hot = vector<float>::Zeros(NSkills); int skill=(int)MathRound(MathRand()/32767.0*(NSkills-1)); one_hot[skill] = 1; State1.AddArray(one_hot);
En esta etapa, transmitiremos los datos de entrada preparados al modelo de Actor y realizaremos una pasada directa a través del modelo. Una pasada directa es el proceso de transmisión de los datos de entrada a través de las capas del modelo y la obtención de los valores de salida correspondientes.
Tras realizar una pasada directa, obtendremos los resultados del modelo que representan las probabilidades de cada acción definidas por el modelo de Actor. Para seleccionar la acción a ejecutar, muestrearemos (seleccionaremos aleatoriamente dadas las probabilidades) una de las acciones posibles en función de las probabilidades obtenidas.
El muestreo de acciones permite al Actor explorar el entorno al máximo considerando cada habilidad. Esto aumentará la variedad de acciones que puede realizar el modelo y ayudará a evitar seleccionar las mismas acciones con demasiada frecuencia. Este planteamiento dota al modelo de mayor flexibilidad y capacidad de adaptación ante las distintas situaciones del entorno.
if(!Actor.feedForward(GetPointer(State1), 1, false)) return; int act = Actor.getSample();
El resto del código del método lo hemos tomado sin ningún cambio de la versión anterior del asesor. El código completo del asesor, incluidos todos sus métodos, se encuentra en el archivo adjunto.
En artículos anteriores ya hemos descrito con detalle el proceso de recopilación de la base de datos de ejemplos, por lo que no nos repetiremos e iremos directamente al desarrollo del asesor experto "DIAYN\Study.mq5" para el entrenamiento de modelos. En su mayor parte hemos usado código desarrollado previamente, pero hemos introducido cambios sustanciales en el método de entrenamiento llamado Train.
Debemos señalar que nos hemos desviado ligeramente del algoritmo original propuesto por los autores del método. En nuestro asesor, entrenaremos el modelo de habilidades y el planificador en paralelo. Obviamente, el discriminador se entrenará junto con ellos según el concepto "Diversity is All You Need".
Así, trataremos de lograr diversidad en las habilidades y comportamientos de los modelos para obtener resultados más sostenibles y eficaces.
Al igual que antes, el entrenamiento del modelo se realizará dentro de un ciclo. El número de iteraciones de este ciclo se definirá en los parámetros externos del asesor experto.
En cada iteración del ciclo de aprendizaje, seleccionaremos aleatoriamente una pasada y un estado de la base de datos de ejemplos. Después de seleccionar un estado, cargaremos los datos históricos sobre los movimientos del precio y los indicadores en el búfer de datos de forma similar a la recopilación de datos en el asesor.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)(((double)MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); State1.AssignArray(Buffer[tr].States[i].state);
También añadiremos los datos sobre el estado de la cuenta y las posiciones abiertas al mismo búfer de datos. Como ya hemos mencionado, convertiremos estos datos en unidades relativas para que los modelos trabajen de forma más fiable con distintos tamaños de cuenta. Esto nos permite unificar la representación del estado de la cuenta y las posiciones abiertas en el modelo, garantizando la comparabilidad para el entrenamiento.
float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; State1.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); State1.Add(Buffer[tr].States[i].account[1] / PrevBalance); State1.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); State1.Add(Buffer[tr].States[i].account[3] / 100.0f); State1.Add(Buffer[tr].States[i].account[4] / PrevBalance); State1.Add(Buffer[tr].States[i].account[5]); State1.Add(Buffer[tr].States[i].account[6]); State1.Add(Buffer[tr].States[i].account[7] / PrevBalance); State1.Add(Buffer[tr].States[i].account[8] / PrevBalance);
Los datos preparados son suficientes para el modelo del planificador, así que podremos realizar una pasada directa por el modelo para determinar la habilidad que se utilizará.
if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } if(!Scheduler.feedForward(GetPointer(State1), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Tras realizar una pasada directa por el modelo del planificador y obtener el vector de probabilidades, generaremos un vector one-hot de identificación de habilidades. Aquí tendremos dos opciones para seleccionar una habilidad: el método de selección "codicioso", que elige la habilidad con mayor probabilidad, y el muestreo, en el que seleccionaremos una habilidad al azar dadas las probabilidades.
En la fase de aprendizaje, le recomendamos utilizar el muestreo para maximizar la exploración del entorno. Esto permitirá al modelo explorar distintas habilidades y descubrir capacidades ocultas y estrategias óptimas. En el aprendizaje, el muestreo ayuda a evitar la convergencia prematura a una habilidad concreta y proporciona actividades exploratorias más variadas, facilitando el entrenamiento de un modelo más flexible y adaptable.
int skill = Scheduler.getSample(); SchedulerResult = vector<float>::Zeros(NSkills); SchedulerResult[skill] = 1; State1.AddArray(SchedulerResult);
El vector de identificación de habilidades resultante se añadirá al búfer de datos de origen, que se transmitirá a la entrada del modelo de Agente. A continuación, se realizará la pasada directa del modelo de Agente para generar la acción. La distribución de probabilidad obtenida del modelo se utilizará para muestrear la acción.
El muestreo de una acción a partir de una distribución de probabilidad permite al modelo de Agente tomar una variedad de decisiones basadas en las probabilidades de cada acción. Esto facilitará la exploración de diferentes estrategias y opciones de comportamiento, y ayudará al modelo a evitar la fijación prematura en una acción concreta.
if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } if(!Actor.feedForward(GetPointer(State1), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } int action = Actor.getSample();
Tras realizar la pasada hacia delante del modelo de Agente, procederemos a generar el búfer de datos para la pasada hacia delante del modelo de Discriminador, que describirá el siguiente estado del sistema. Al igual que en el paso anterior, empezaremos cargando los datos históricos en el búfer. En este caso, simplemente copiaremos sin ningún problema en el búfer de datos los datos históricos de la base de datos de ejemplos, ya que estas métricas son independientes del modelo y de las habilidades utilizadas.
State1.AssignArray(Buffer[tr].States[i + 1].state);
Tenemos algunas dificultades para describir el estado de la cuenta: no podemos limitarnos a tomar datos de la base de datos de ejemplo, ya que rara vez coincidirán con la acción seleccionada. Del mismo modo, no podemos sustituir simplemente una acción de la base de datos de ejemplos, ya que el discriminador analizará el estado recibido como entrada y lo relacionará con la habilidad usada. Aquí es donde surge la desconexión.
Sin embargo, debemos señalar que el resultado del discriminador solo se utiliza como función de recompensa. No exigimos una gran precisión a la hora de describir el nuevo estado del balance de la cuenta. En cambio, necesitaremos que los datos sean comparables entre las distintas acciones. Por ello, podemos aproximar los valores de los indicadores del estado de la cuenta basándonos en el estado anterior, considerando el tamaño de la última vela y la acción seleccionada. Ya tenemos todos los datos necesarios para el cálculo.
En el primer paso, copiaremos los datos de la cuenta del estado anterior y calcularemos el beneficio para una posición larga cuando el precio se mueve en la magnitud de la última vela. Aquí no tendremos en cuenta el volumen de posición específico y su dirección, esto se considerará más adelante.
vector<float> account; account.Assign(Buffer[tr].States[i].account); int bar = (HistoryBars - 1) * BarDescr; double cl_op = Buffer[tr].States[i + 1].state[bar]; double prof_1l = SymbolInfoDouble(_Symbol, SYMBOL_TRADE_TICK_VALUE_PROFIT) * cl_op / SymbolInfoDouble(_Symbol, SYMBOL_POINT);
A continuación, realizaremos ajustes en los datos del estado de la cuenta según la acción seleccionada. El caso más sencillo es el cierre de posiciones. Simplemente añadiremos la ganancia o pérdida acumulada al estado actual de la cuenta. El valor resultante se transferirá a los elementos de equidad y margen libre, mientras que los demás indicadores se pondrán a cero.
Al ejecutar una operación comercial, deberemos aumentar la posición correspondiente. Como todas las transacciones se ejecutan con un lote mínimo, aumentaremos el tamaño de la posición correspondiente en el lote mínimo.
Para calcular la ganancia o pérdida acumulada para cada dirección, multiplicaremos la ganancia calculada anteriormente para un lote por el tamaño de la posición correspondiente. Dado que el beneficio de una posición larga se ha calculado antes, sumaremos este valor a la ganancia acumulada anterior para las posiciones largas y lo restaremos para las posiciones cortas. El beneficio total de una cuenta se obtendrá sumando los beneficios de las distintas áreas.
La equidad se calculará como la suma del balance y los beneficios acumulados.
Las cifras de margen no se modificarán, ya que el cambio por el lote mínimo será insignificante.
Al mantener una posición, el planteamiento será similar, salvo por el cambio en el volumen de la posición.
switch(action) { case 0: account[5] += (float)SymbolInfoDouble(_Symbol, SYMBOL_VOLUME_MIN); account[7] += account[5] * (float)prof_1l; account[8] -= account[6] * (float)prof_1l; account[4] = account[7] + account[8]; account[1] = account[0] + account[4]; break; case 1: account[6] += (float)SymbolInfoDouble(_Symbol, SYMBOL_VOLUME_MIN); account[7] += account[5] * (float)prof_1l; account[8] -= account[6] * (float)prof_1l; account[4] = account[7] + account[8]; account[1] = account[0] + account[4]; break; case 2: account[0] += account[4]; account[1] = account[0]; account[2] = account[0]; for(bar = 3; bar < AccountDescr; bar++) account[bar] = 0; break; case 3: account[7] += account[5] * (float)prof_1l; account[8] -= account[6] * (float)prof_1l; account[4] = account[7] + account[8]; account[1] = account[0] + account[4]; break; }
Tras ajustar los datos del balance y las posiciones abiertas, los añadiremos al búfer de datos. Para ello, como antes, convertiremos sus valores en unidades relativas y realizaremos una pasada directa del modelo de discriminador.
PrevBalance = Buffer[tr].States[i].account[0]; PrevEquity = Buffer[tr].States[i].account[1]; State1.Add((account[0] - PrevBalance) / PrevBalance); State1.Add(account[1] / PrevBalance); State1.Add((account[1] - PrevEquity) / PrevEquity); State1.Add(account[3] / 100.0f); State1.Add(account[4] / PrevBalance); State1.Add(account[5]); State1.Add(account[6]); State1.Add(account[7] / PrevBalance); State1.Add(account[8] / PrevBalance); //--- if(!Discriminator.feedForward(GetPointer(State1), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Tras realizar una pasada directa del discriminador, compararemos sus resultados con el vector one-hot que contiene la identificación de la habilidad utilizada en la pasada directa del agente.
Discriminator.getResults(DiscriminatorResult);
Actor.getResults(ActorResult);
ActorResult[action] = DiscriminatorResult.Loss(SchedulerResult, LOSS_CCE);
El valor de entropía cruzada obtenido comparando los dos vectores se utilizará como recompensa por la acción seleccionada. Esta recompensa nos permitirá realizar la pasada inversa en el modelo del agente y actualizar sus ponderaciones para mejorar la elección de acciones futuras.
Result.AssignArray(ActorResult); State1.AddArray(SchedulerResult); if(!Actor.backProp(Result, DiscountFactor, GetPointer(State1), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
El vector one-hot de identificación que representa la habilidad utilizada, será el valor objetivo al entrenar el modelo de discriminador. Utilizaremos este vector como objetivo para entrenar el discriminador para que clasifique correctamente los estados del sistema según la habilidad seleccionada.
Result.AssignArray(SchedulerResult); if(!Discriminator.backProp(Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Solo usaremos los cambios del balance de la cuenta como recompensa para el planificador. Calcularemos este valor con precisión y lo comunicaremos como valores relativos. Sin embargo, a diferencia del agente, que solo recibe la recompensa por la acción seleccionada, nosotros distribuiremos la recompensa del planificador entre todas las habilidades según las probabilidades de seleccionar cada habilidad. Así, la recompensa del planificador se repartirá entre las habilidades según sus probabilidades de selección.
Result.AssignArray(SchedulerResult * ((account[0] - PrevBalance) / PrevBalance)); if(!Scheduler.backProp(Result, DiscountFactor, GetPointer(State1), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Al final de cada iteración del ciclo de aprendizaje, generaremos un mensaje informativo con los datos sobre el proceso de aprendizaje. Este mensaje se representará en el gráfico para visualizar el proceso. A continuación, pasaremos a la siguiente iteración, continuando el proceso de entrenamiento.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Scheduler", iter * 100.0 / (double)(Iterations), Scheduler.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Discriminator", iter * 100.0 / (double)(Iterations), Discriminator.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Cuando lleguemos al final del proceso de aprendizaje, limpiaremos los mensajes en el gráfico, eliminando los datos de información anteriores. A continuación, se iniciará la finalización del asesor.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Scheduler", Scheduler.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Discriminator", Discriminator.getRecentAverageError()); ExpertRemove(); //--- }
Al final del artículo, adjuntamos el código completo de todos los métodos y funciones utilizados en el asesor experto. Podrá consultarlo para obtener más información.
3. Simulación
El modelo se ha entrenado con datos históricos del instrumento EURUSD con el marco temporal H1 durante los cuatro primeros meses de 2023. Durante el entrenamiento, hemos encontrado un error no indicado en el rendimiento del modelo de agente relacionado con la política de recompensas que puede llevar a un crecimiento sin límites de las mismas. Sin embargo, el proceso de entrenamiento sigue estando controlado por el rendimiento de los modelos de programador y discriminador.
La segunda característica del proceso es que no existe una correlación directa entre la elección del programador y la acción realizada. La elección del planificador influye más en la elección de la estrategia que en la acción concreta, y esto significa que el planificador definirá un enfoque general para la toma de decisiones, mientras que la acción específica será elegida por el modelo de agente basándose en el estado actual y la habilidad elegida.
Para probar el rendimiento del modelo entrenado, utilizaremos los datos de las dos primeras semanas de mayo de 2023 que no se incluyeron en la muestra de entrenamiento pero que siguen de cerca el periodo de entrenamiento. Este enfoque permitirá evaluar el rendimiento del modelo con los nuevos datos, que seguirán siendo comparables porque no existe desfase temporal entre las muestras de entrenamiento y las de prueba.
Para las pruebas hemos utilizado el asesor experto modificado "DIAYN\Test.mq5". Los cambios realizados solo han afectado a los algoritmos de preparación de datos según la arquitectura del modelo y al proceso de preparación de los datos de entrada. También se ha modificado la secuencia de llamada de las pasadas directas del modelo. El proceso se estructurará de forma similar a los asesores descritos anteriormente para recopilar una base de ejemplos y entrenar los modelos. El código detallado de la asesor está disponible en el archivo adjunto.


La prueba del modelo entrenado ha dado como resultado un pequeño beneficio, con un factor de beneficio de 1,61 y un factor de recuperación de 3,21. Durante las 240 barras del periodo de prueba, el modelo ha realizado 119 operaciones, y casi el 55% de ellas se han cerrado con beneficios.
El planificador ha desempeñado un papel importante en la consecución de estos resultados al distribuir uniformemente el uso de todas las habilidades. Debemos señalar que se ha utilizado una estrategia codiciosa para seleccionar las acciones y habilidades. El modelo ha seleccionado la acción más rentable según el estado actual.

Conclusión
En este artículo hemos presentado un método de entrenamiento de modelos comerciales basado en el método DIAYN (Diversity Is All You Need), que permite entrenar el modelo con una amplia variedad de habilidades sin vincularse a una tarea específica.
El modelo se ha entrenado usando los datos históricos del instrumento EURUSD utilizando el marco temporal H1 para los 4 primeros meses de 2023.
Durante el entrenamiento del modelo, hemos comprobado que no existe una correlación directa entre la elección del planificador y la acción realizada. No obstante, el proceso de aprendizaje se ha mantenido controlado y ha mostrado cierta capacidad por parte del modelo para operar con rentabilidad.
Una vez completado el entrenamiento, el modelo se ha probado con nuevos datos que no formaban parte de la muestra de entrenamiento. Los resultados de las pruebas han mostrado un pequeño beneficio, un factor de beneficio de 1,61 y un factor de recuperación de 3,21. Sin embargo, debemos seguir optimizando y mejorando la estrategia del modelo para lograr resultados mejores y más estables.
Un aspecto importante del modelo ha sido el planificador, que distribuía uniformemente el uso de todas las habilidades. Esto subraya la importancia de desarrollar estrategias eficaces de toma de decisiones para lograr resultados comerciales satisfactorios.
En general, el enfoque presentado para el entrenamiento de modelos comerciales basado en el método DIAYN ofrece interesantes perspectivas para el desarrollo del comercio automatizado. Nuevas investigaciones y mejoras de este planteamiento pueden ayudarnos a conseguir modelos comerciales más eficaces y rentables.
Enlaces
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | Study.mql5 | Asesor | Asesor de entrenamiento de modelos |
| 3 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 4 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema. |
| 5 | FQF.mqh | Biblioteca de clases | Biblioteca de clases de organización de modelos completamente parametrizada |
| 6 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/12698
- Aplicaciones de trading gratuitas
- VPS fórex gratuito por 24 horas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso